(some (context))
In the early 60s, computer scientist John McCarthy developed a programming system called LISP.
This system defined this new notion of syntax called: S-expression or sexpr, for short.
If you have never written in a LISP, this is what a sexpr looks like: (function param1 param2)
On the left-most side of the parenthesis, we have the function to apply, and the rest are its arguments.
Its simple, concise, and practical.
One question arises: how do we do arithmetic? Simple: (+ 1 2) evaluates to: 3
You can also nest expressions together, and create bigger expressions,
like: (* (- 14 5) (+ 4 6 3))
You get the idea…
What is an sexpr, exactly?
A sexpr is just an n-ary tree, where the leaves are atoms, and the nodes that branch are other sexprs.
An atom is almost like a primitive type, except it also includes symbols, bound variables and some other oddities specific to each language
Don’t believe that (+ (* 2 3) 7) is just a tree?
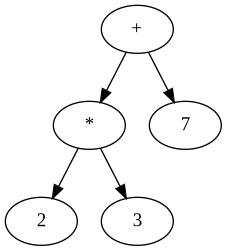
How about now.
More precisely, you could define an S-expression using algebraic data types as:
1
2
3
|
type sexp =
| Atom of string
| SList of sexp list
|
LISP, the family
LISP isn’t only a language, it’s a family of languages. Pretty much, every language that uses parenthesized prefix notation is considered a LISP.
This is why I don’t say “in LISP” but rather “in a LISP”.
Modern LISPs include: Racket, Scheme, Clojure and Common Lisp.
“This is hideous, how can you like it so much?”
Truth to be told, I didn’t at first. My first experience with a LISP was with a newer dialect, called Racket.
In my freshmen year at Northeastern University I took the famous Fundies 1 course, where we read through the HtDP book and learned how to design programs, functionally, in the language.
I hated the first few weeks. The language we used constrained me too much, it didn’t show me its shiny side and didn’t let me play with its internals.
That all changed when I discovered that sexprs are not only part of the grammar, they are part of the data.
That meant that an AST can be a sexpr, and that AST had sexprs with sexprs.
That meant I could write a LISP interpreted by a LISP, interpreted by a LISP, interpreted by a LISP …
That, for me, was mind-blowing and my passion for PL emerged.
Macros
Modern LISPs have this notion of “macros”, where you can write pieces of code that get cut and glued together with expressions and symbols.
These macros make the code more concise and abstract, and give the programmer more flexibility over the language.
This is very common amongst LISPs, in fact, in Racket, the boolean or and and operations aren’t functions or primitives, those are macros (for short-circuiting reasons I believe).
You adapt the language to the problem, not the problem to the language
Usually, programmers tend to program around the language they are using. If you are writing in Java, you are going to see a lot of SingletonAbstractFactoryStrategyHelloWorld situations. If you are writing in Rust (I love Rust, please don’t come after me) you will often have
Box<(dyn std::error::Error, Arc<RwLock<IJustWantedConcurrency>>)> moments.
Meanwhile, LISP code all look different, this is because its programmer didn’t adapt the problem to the language, they adapted the language to the problem.
An Example
Let’s take finite-state machines as an example. With finite-state machines, you can create state in a purely functional language, without using any mutation or side effects.
Let’s say I want to simulate traffic lights with a finite state automata, the state should become green after being red, yellow after being green, and red after yellow, repeat…
My code in Racket will roughly look like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
(define (traffic-state tape)
(local ([define (start tape)
(cond
[(empty? tape) #true]
[else
(case (first tape)
[("green") (middle (rest tape))]
[else #false])])]
[define (middle tape)
(cond
[(empty? tape) #false]
[else
(case (first tape)
[("yellow") (end (rest tape))]
[else #false])])]
[define (end tape)
(cond
[(empty? tape) #false]
[else
(case (first tape)
[("red") (start (rest tape))]
[else #false])])]
[define (process state tape)
(cond
[(string=? state "Start") (start tape)]
[(string=? state "Middle") (middle tape)]
[(string=? state "End") (end tape)])])
(process "Start" tape)))
|
In essence, we have this function called tree-state that takes in an init state, either "Start", "Middle" or "End", and a tape with the history of the states the traffic light needs to go through.
This function will produce #true if the states are well-formed (i.e. in the right order:
... -> "green" -> "yellow" -> "red" -> ... ending with "red") or #false if they aren’t.
For example, (traffic-state '("green" "yellow" "red" "green" "yellow" "red")) produces #true,
but (traffic-state '("green" "yellow" "green" "red")) or (traffic-state '("green" "yellow" "red" "green")) produces #false.
If we wanted to adapt this state machine to another problem or add another case, we would have to change a lot of things.
This is where macros come into play. Let’s define a macro to help us (credits, PDF page 10):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
(define-syntax state-automata
(syntax-rules (: ->)
[(state-automata init-state
(state-name : (state-case -> next-state) ...)
...
final-state)
(lambda (tape)
(local ([define (state-name tape)
(cond
[(empty? tape) (equal? state-name final-state)]
[else
(case (first tape)
[(state-case) (next-state (rest tape))]
...
[else #false])])]
...)
(init-state tape)))]))
|
And, we redefine our traffic-state function as:
1
2
3
4
5
6
|
(define traffic-state/v2
(state-automata START
(START : ("green" -> MIDDLE))
(MIDDLE : ("yellow" -> END))
(END : ("red" -> START))
START))
|
Much better!
Interestingly, if we count the lines of our unabstracted function, we get 28 lines of code.
Meanwhile, the macro and the newer function are only 23 lines of code combined.
*laughs uncontrollably while staring at Java’s abstract classes*
The syntax of our state-automata macro is roughly:
1
2
3
4
|
(state-automata initial-state
(state-name : (case-name -> state-name) ...)
...
end-statisfied-state)
|
This is all thanks to the power of S-expressions, they let us match and substitute nodes in the AST with ease and granular control.
Macros are not only part of LISPs, other languages have them as well, but they are not as advanced.
For example, here I have a macro in C that will produce the size of an array given the array and the type:
1
2
3
4
5
6
|
#define len(arr, type) (sizeof(arr) / sizeof(type))
int main() {
int arr[3] = {1, 2, 3};
return len(arr, int);
}
|
I have picked this example because types in C are not values, yet you can pass them into this macro.
How C handles macros is very cave-man-like: when this macro is reached by the pre-processor, the raw source code gets pasted, nothing more nothing less.
Let’s check out a more “advanced” language, Rust. In Rust, we can define some pretty cool macros, even recursive ones.
For example, here is a linked-list implementation that has a macro for initialization that takes in variadic parameters (with list implementations omitted for conciseness):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
#[macro_export]
macro_rules! list { // it's recursive!!!
() => { // base case
Empty::new()
}; // reads variadic args like a cons list
( $first:expr $( , $rest:expr )* ) => {{
Cons::new($first, Box::new(list!($( $rest ),*)))
}};
}
pub trait List<T> { /* omitted */ }
struct Empty;
impl Empty {
fn new() -> Self {
Empty
}
}
struct Cons<T> {
first: T,
rest: Box<dyn List<T>>,
}
impl<T> Cons<T> {
pub fn new(first: T, rest: Box<dyn List<T>>) -> Self {
Self { first, rest }
}
}
#[cfg(test)]
mod tests {
#[test]
fn it_works() {
let l123 = Cons::new( // ughh.... this is ugly!!!!
1,
Box::new(Cons::new(2, Box::new(Cons::new(3, Box::new(Empty::new()))))),
);
let l123_macro = list!(1, 2, 3); // calling the macro
assert_eq!(l123_macro, l123); // lets just imagine List derives PartialEQ...
}
}
|
Here is another Rust example where we reduce code duplication by using macros for trait implementations (snippet from SxLang’s source code):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
/// Defines a trait for a tag, which allows the tag to be wrapped into another tag.
pub trait TagWrappable {
type WrappedAST;
/// Gets the tag wrapped into this tag.
fn take_ast(self) -> Self::WrappedAST
where
Self: Sized;
/// Wraps the given ast into this tag.
fn wrap(ast: Self::WrappedAST) -> Self;
/// Wraps the given ast node with a previous wrappable tag, into this tag
fn change_wrap<IntoWrap: TagWrappable<WrappedAST = Self::WrappedAST>>(self) -> IntoWrap
where
Self: Sized;
}
/// Defines a tag for an AST node, which symbolizes that the node was uniquely tagged.
pub struct Tagged<D>(pub ASTNode<D>);
/// Defines a tag for an AST node, which symbolizes that the node was well-formed, thus the node is
/// well-formed by the definition of the language.
pub struct WellFormed<D>(pub ASTNode<D>);
/// Defines a tag for an AST node, which symbolizes that the node was typechecked, thus the node is
/// type safe by the definition of the type system.
pub struct TypeChecked<D>(pub ASTNode<D>);
/// Macro to implement tag wrappable for a given type.
macro_rules! impl_tagwrappable {
($t:ident) => {
impl<D> TagWrappable for $t<D> {
type WrappedAST = ASTNode<D>;
fn wrap(ast: Self::WrappedAST) -> Self {
$t(ast)
}
fn change_wrap<IntoWrap: TagWrappable<WrappedAST = Self::WrappedAST>>(
self,
) -> IntoWrap {
IntoWrap::wrap(self.take_ast())
}
fn take_ast(self) -> Self::WrappedAST {
self.0
}
}
};
}
// these macros implement the trait for all three structs
impl_tagwrappable!(TypeChecked);
impl_tagwrappable!(WellFormed);
impl_tagwrappable!(Tagged);
|
Cool! This gets close to a LISP, but not quite. Rust macros can get pretty painful to write, as you might have noticed. Additionally, Rust has some problems with blending together the macro system and the type system, as generics get eagerly type-checked, but macros are lazily expanded. This is why we were able to pull off the $t<D> trick in the example above. We wouldn’t be able to change $t<D> to just $t and expand the macro with impl_tagwrappable!(TypeChecked<D>), as the generic parameter D would need to be evaluated first (the syntax does not allow you to do this anyway).
Programming Language Development
Writing macros is like writing mini programming languages, but why do mini when you can do big?
sexprs are perfect for creating programming languages of any scale from scratch.
The reason is simple: writing the parser is the worst part of writing a language, especially if you are just making a toy language.
With sexprs, you can just make a trivial recursive function that transforms s-expression concrete syntax into an abstract syntax tree.
Sure, you could call that a parser, but it’s not the same thing as using lex and yacc.
Here is one example “parser” in Racket for a sexpr-based grammar to an AST (some functions omitted):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
(define (parse-type sexp)
(match sexp
['number (numType)]
['bool (boolType)]
[`(,args ... -> ,ret) (funType (map parse-type args)
(parse-type ret))]
[else (error 'parse (string-append
(symbol->string sexp)
" is not a parsable type"))]))
(define (parse sexp)
(match sexp
['true (boolE #t)]
['false (boolE #f)]
[n #:when (number? n) (numE n)]
[id-sym #:when (symbol? id-sym) (idE id-sym)]
[`(,op ,l ,r) #:when (binop-symbol? op)
(binopE (binop-table op) (parse l) (parse r))]
[`(fun ([,params : ,param-types] ...) : ,ret-type ,body)
(if (symbol-duplicates? params)
(error 'parse "duplicate id in fun params")
(funE params (map parse-type param-types)
(parse body) (parse-type ret-type)))]
[`(loc ([,bound-ids : ,ids-types ,named-exprs] ...) : ,ret-type ,body)
(if (symbol-duplicates? bound-ids)
(error 'parse "duplicate id in loc bound ids")
(appE
(funE bound-ids (map parse-type ids-types) (parse body) (parse-type ret-type))
(map parse named-exprs)))]
[`(if ,cond-expr ,true-body ,false-body)
(ifE (parse cond-expr) (parse true-body) (parse false-body))]
[`(rec ([,bound-ids : ,ids-types ,fun-exprs] ...) : ,ret-type ,body)
(if (symbol-duplicates? bound-ids)
(error 'parse "duplicate id in rec bound ids")
(recE
(map (lambda (id expr) (recBind id (parse expr))) bound-ids fun-exprs)
(map parse-type ids-types)
(parse body)
(parse-type ret-type)))]
[else (error 'parse (string-append
(symbol->string sexp)
" is not a parsable expression"))]))
|
And here is a parser for position-annotated S-Expression in Rust (some parts omitted, parse_primitive is straight-forward):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
|
impl ASTParser {
pub fn parse_from_sexpr<'a>(
input: &'a Sexpr<Span>,
) -> Result<ASTNode<Span<'a>>, ParsingError<'a>> {
match input {
Sexpr::Atom(a, _) => Self::parse_primitive(a),
Sexpr::List(list, span) => Self::parse_list(list, span),
}
}
fn parse_list<'a>(
input: &'a [Sexpr<Span>],
outer_span: &'a Span<'a>,
) -> Result<ASTNode<Span<'a>>, ParsingError<'a>> {
match input {
[Sexpr::Atom(Atom::Symbol(letstr, _), _), Sexpr::List(letbinds, _), expr]
if let ("let", Ok(result_binds)) = (letstr.as_ref(), Self::parse_letbinds(letbinds)) => {
Ok(ASTNode::Let(result_binds, Box::new(Self::parse_from_sexpr(expr)?), outer_span.clone()))
}
[Sexpr::Atom(Atom::Symbol(ref s, _), _), expr]
if let Ok(op) = UnaryOp::from_str(s) =>
{
Ok(ASTNode::UnaryOp(
op,
Box::new(Self::parse_from_sexpr(expr)?),
outer_span.clone(),
))
}
[Sexpr::Atom(Atom::Symbol(ref s, _), _), e1, e2]
if let Ok(op) = BinaryOp::from_str(s) =>
{
Ok(ASTNode::BinaryOp(
op,
Box::new(Self::parse_from_sexpr(e1)?),
Box::new(Self::parse_from_sexpr(e2)?),
outer_span.clone(),
))
}
[Sexpr::Atom(Atom::Symbol(ref s, _), _), Sexpr::List(params, _), expr] if s == "fun" =>
{
let mut parsed_params = Vec::new();
for param in params {
if let Sexpr::Atom(Atom::Symbol(id, _), _) = param {
parsed_params.push(id.to_string());
} else {
return Err(ParsingError::InvalidSyntax(
param.get_decorator().clone(),
param.to_string(),
Some("expected a parameter".to_string()),
));
}
}
Ok(ASTNode::Function(parsed_params, Box::new(Self::parse_from_sexpr(expr)?), outer_span.clone()))
}
// else, must be a func call, or something bad
[first, rest @ ..] => {
let mut args = Vec::new();
for expr in rest {
args.push(Self::parse_from_sexpr(expr)?);
}
Ok(ASTNode::Call(
Box::new(Self::parse_from_sexpr(first)?),
args,
outer_span.clone(),
))
},
[] => Err(ParsingError::InvalidSyntax(
outer_span.clone(),
"()".to_string(),
Some("expected an expression".to_string()),
)),
}
}
}
|
Conclusion
Overall, I think that S-expressions are a great tool for many needs, PL or not PL, and everyone should know how and when to use them.
1
2
3
4
|
[federico:~]$ racket
Welcome to Racket v8.5 [cs].
> (better? 'parens)
"You decide."
|
